Przystępność Deepseek to mit: rewolucyjna sztuczna inteligencja kosztowała 1,6 miliarda dolarów na rozwój
Zaskakująco opłacalny model AI Deepseek wyzwala gigantów branżowych. Samozwańcze koszty szkolenia w wysokości 6 milionów dolarów dla Deepseek V3, przy użyciu tylko 2048 GPU, początkowo wydawało się rewolucyjne. Jednak bliższe spojrzenie ujawnia znacznie większą inwestycję.
 Obraz: engame.com
Obraz: engame.com
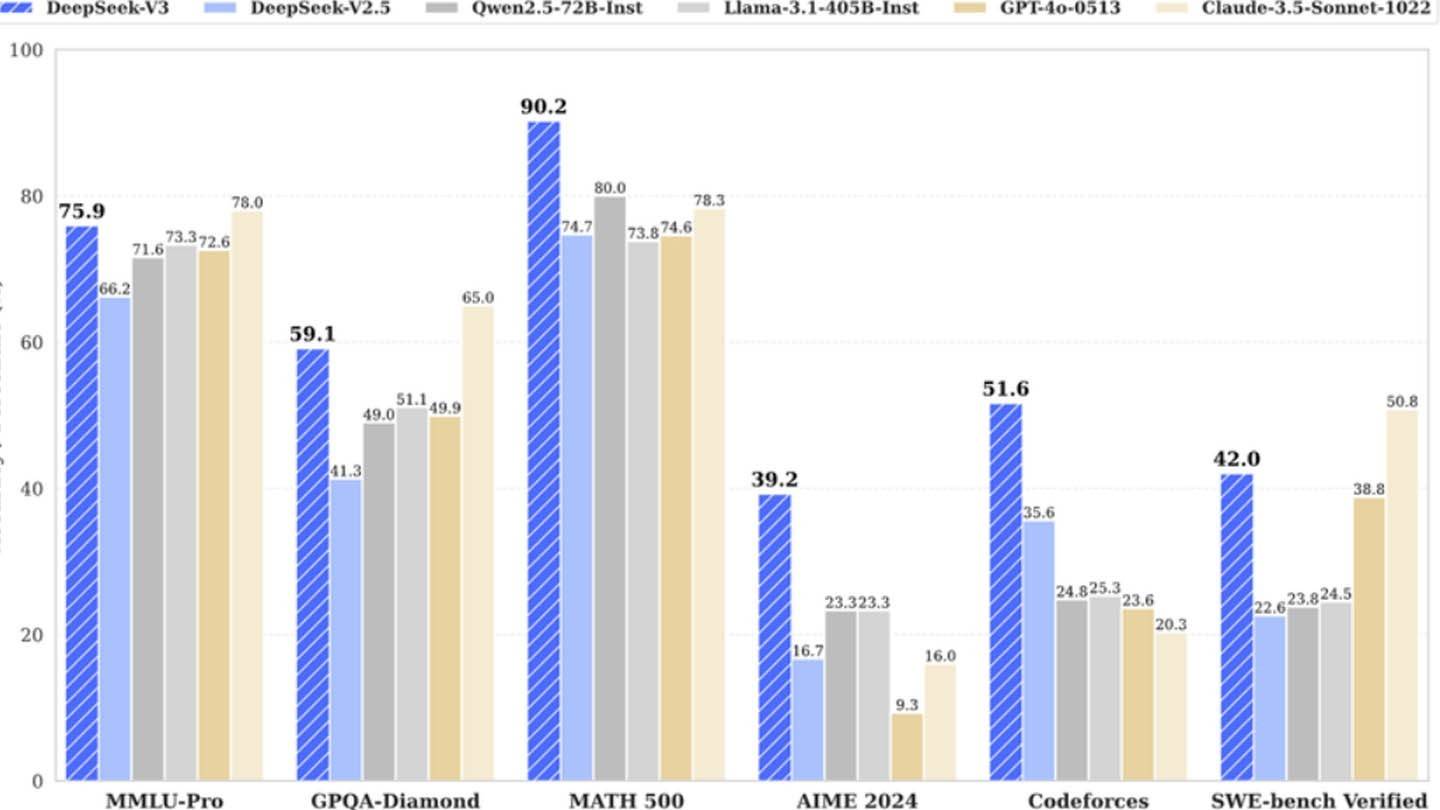
DeepSeek V3 wykorzystuje innowacyjne technologie: Prognozowanie wielofunkcyjne (MTP) w celu zwiększenia dokładności i wydajności; Mieszanka ekspertów (MOE) , wykorzystująca 256 sieci neuronowych (osiem aktywowanych na token); i wielopłaska ukryta uwaga (MLA) dla lepszej ekstrakcji informacji. Postępy te przyczyniają się do konkurencyjnych wyników modelu.
 Obraz: engame.com
Obraz: engame.com
W przeciwieństwie do początkowych twierdzeń, semianaliza ujawniła wykorzystanie Deepseek około 50 000 GPU NVIDIA, w tym jednostek H800, H100 i H20, rozłożonych na wiele centrów danych. Ta infrastruktura stanowi znaczną inwestycję w wysokości około 1,6 miliarda dolarów, a wydatki operacyjne szacują na 944 mln USD.
 Obraz: engame.com
Obraz: engame.com
Deepseek, spółka zależna od wysokiej flyer, jest właścicielem swoich centrów danych, zapewniając kontrolę i przyspieszając innowacje. Jego samofinansowana natura sprzyja zwinności. Wysokie wynagrodzenie, przekraczające 1,3 miliona dolarów rocznie dla niektórych naukowców, przyciągają najlepsze talenty z chińskich uniwersytetów.
Liczba 6 milionów dolarów odzwierciedla jedynie koszty GPU przed treningiem, z wyłączeniem badań, udoskonalania, przetwarzania danych i infrastruktury. Całkowita inwestycja AI Deepseek przekracza 500 milionów dolarów. Mimo to jego usprawniona struktura umożliwia wydajne innowacje.
 Obraz: engame.com
Obraz: engame.com
Podczas gdy sukces Deepseek pokazuje potencjał dobrze finansowanych niezależnych firm AI, narracja „przyjazna budżetowi” jest myląca. Kluczowe są miliardy inwestycji, przełomów technologicznych i wykwalifikowanego zespołu. Jednak nawet przy tych znacznych zasobach koszty Deepseek pozostają znacznie niższe niż konkurenci, takie jak zgłoszone 100 milionów dolarów wydanych na Chatgpt4o w porównaniu z 5 milionami dolarów Deepseek na R1. Rozbieżność podkreśla względną wydajność Deepeek, pomimo znacznej ogólnej inwestycji.
-
 Świat wariantów czarodziejów Daphne nadal rozwija się o ekscytujące aktualizacje. Niedawno gra świętowała osiągnięcie miliona pobrań i otworzyła swój oficjalny sklep. Teraz najnowsza aktualizacja przedstawia nowego legendarnego poszukiwacza przygód, szybkiego Blackstar Savia. Z nazwą, która jest dość kęs, SaviaAutor : Lillian May 16,2025
Świat wariantów czarodziejów Daphne nadal rozwija się o ekscytujące aktualizacje. Niedawno gra świętowała osiągnięcie miliona pobrań i otworzyła swój oficjalny sklep. Teraz najnowsza aktualizacja przedstawia nowego legendarnego poszukiwacza przygód, szybkiego Blackstar Savia. Z nazwą, która jest dość kęs, SaviaAutor : Lillian May 16,2025 -
 Jeśli nurkujesz w pełnym akcji świat *rywali Marvela *, prawdopodobnie natkniesz się na różne osiągnięcia i wyróżnienia, które mogą sprawić, że drapisz się po głowie. Jednym terminem, który może przyciągnąć uwagę, jest „as”. Rozbijmy to, co ACE oznacza w * Marvel Rivals * i jak możesz go zdobyć. Tabela conAutor : Audrey May 16,2025
Jeśli nurkujesz w pełnym akcji świat *rywali Marvela *, prawdopodobnie natkniesz się na różne osiągnięcia i wyróżnienia, które mogą sprawić, że drapisz się po głowie. Jednym terminem, który może przyciągnąć uwagę, jest „as”. Rozbijmy to, co ACE oznacza w * Marvel Rivals * i jak możesz go zdobyć. Tabela conAutor : Audrey May 16,2025
-
 Street Karate Fighter GamePobierać
Street Karate Fighter GamePobierać -
 Bible Word CrossPobierać
Bible Word CrossPobierać -
 Keeper of the Sun and MoonPobierać
Keeper of the Sun and MoonPobierać -
 How I became a femalePobierać
How I became a femalePobierać -
 Wild Time by Michigan LotteryPobierać
Wild Time by Michigan LotteryPobierać -
 Giggle Babies - Toddler CarePobierać
Giggle Babies - Toddler CarePobierać -
 Merge Magic Princess: Tap GamePobierać
Merge Magic Princess: Tap GamePobierać -
 Vegetables QuizPobierać
Vegetables QuizPobierać -
 Ocean Realm: Abyss ConquerorPobierać
Ocean Realm: Abyss ConquerorPobierać -
 Skate SurfersPobierać
Skate SurfersPobierać











- Gwiazdy WWE dołączają do składu Call of Duty Warzone: Mobile
- „Grand Outlaws uwalnia chaos i przestępczość podczas Android Soft Launch”
- Ultimate Guide to Dead Rails wyzwania [Alpha]
- Piosenka gier wideo przewyższa 100 milionów strumieni na Spotify
- Nagroda Pocket Gamer People's Choice Award 2024: Gra ujawniona
- Nadchodzące gier spektakularne dla konsol Xbox