DeepSeek的负担能力是一个神话:革命性的AI实际上花费了16亿美元
作者 : Max
Feb 26,2025
DeepSeek令人惊讶的具有成本效益的AI模型挑战了行业巨头。该公司自称为DeepSeek V3的600万美元培训成本,最初仅使用2048 GPU,这似乎是革命性的。但是,近距离的外观显示出更大的投资。
 图像:ensigame.com
图像:ensigame.com
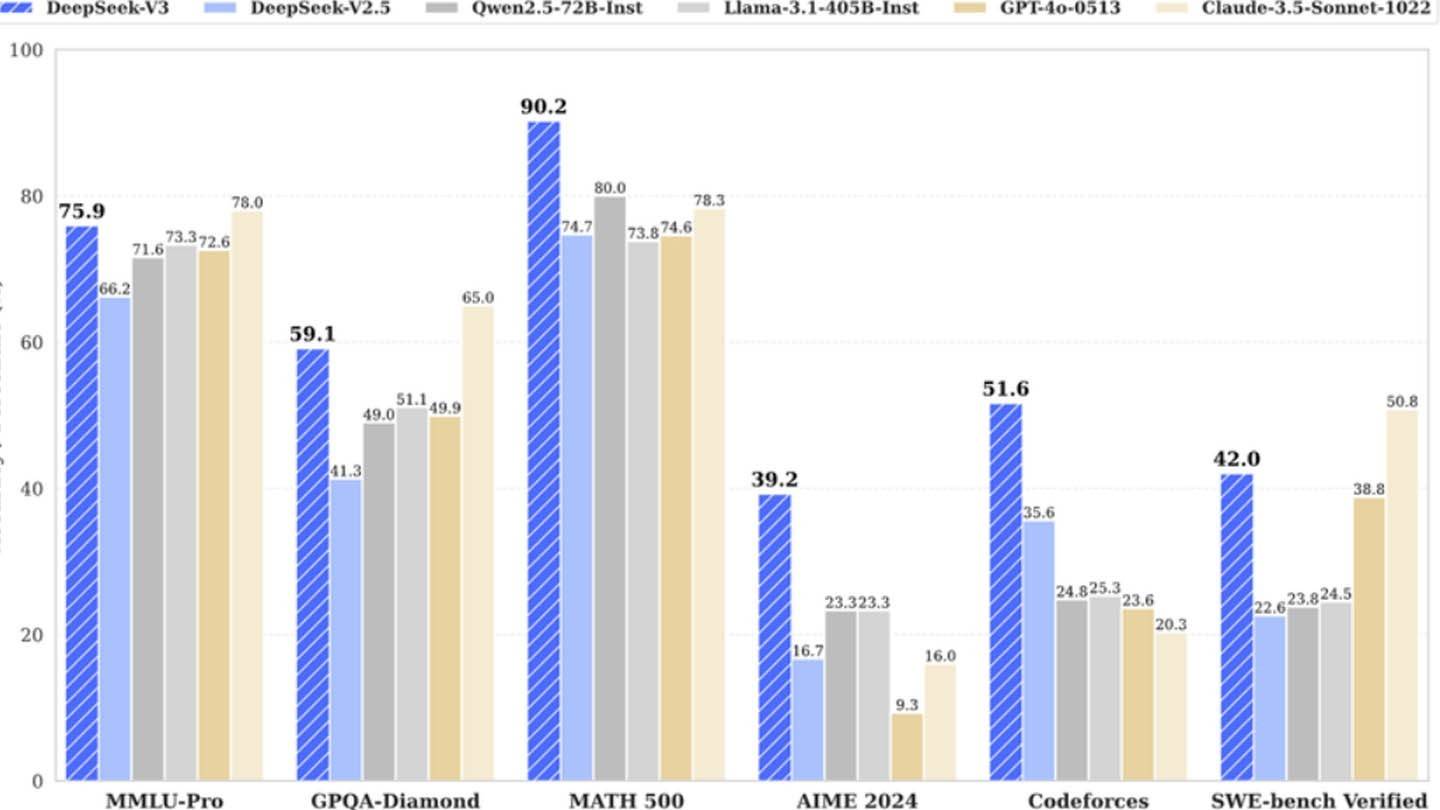
DeepSeek V3利用创新技术:多token预测(MTP),以提高准确性和效率; 专家(MOE)的混合物,利用256个神经网络(八个激活的令牌); 多头潜在注意(MLA),以改善信息提取。这些进步有助于模型的竞争性能。
 图像:ensigame.com
图像:ensigame.com
与最初的主张相反,半分析显示,DeepSeek使用了大约50,000个NVIDIA GPU,包括H800,H100和H20单位,分布在多个数据中心。该基础设施代表大约16亿美元的大量投资,运营费用估计为9.44亿美元。
 图像:ensigame.com
图像:ensigame.com
高级飞行者的子公司DeepSeek拥有其数据中心,提供控制和加速创新。它的自我资助的性质促进了敏捷性。对于一些研究人员来说,高薪高薪,每年超过130万美元,吸引了中国大学的顶尖人才。
这笔600万美元的数字仅反映了培训前的GPU成本,不包括研究,改进,数据处理和基础架构。 DeepSeek的AI总投资超过了5亿美元。尽管如此,其简化的结构可以有效地创新。
 图像:ensigame.com
图像:ensigame.com
虽然DeepSeek的成功展示了资金庞大的独立AI公司的潜力,但“预算友好”的叙述是误导性的。数十亿美元的投资,技术突破和熟练的团队是关键因素。但是,即使有了这些大量资源,DeepSeek的成本仍大大低于竞争对手,例如在Chatgpt4o上花费了1亿美元的竞争对手,而DeepSeek的R1 $ 500万。尽管总体投资大量投资,但差距强调了DeepSeek的相对效率。
最新文章
-
 在《死亡空间:野兽》中,玩家将再次扮演凯尔·克兰(Kyle Crane),探索险象环生的卡斯托森林,这是一款独立的动作冒险角色扮演游戏。深入了解该游戏的最新更新与发展动态!← 返回《死亡空间:野兽》主条目死亡空间:野兽新闻2025年7月21日⚫︎ Techland发布了《死亡空间:野兽》的全新预告片,以讽刺幽默的方式展现了即将登场的卡斯托森林场景。视频由海狸博伯(Bober)主持,呈现出一则欢快的旅游宣传片风格,但很快便陷入混乱,该地区爆发的僵尸危机成为画面的主导。阅读更多:《死亡空间:野兽》最作者 : Ethan May 10,2026
在《死亡空间:野兽》中,玩家将再次扮演凯尔·克兰(Kyle Crane),探索险象环生的卡斯托森林,这是一款独立的动作冒险角色扮演游戏。深入了解该游戏的最新更新与发展动态!← 返回《死亡空间:野兽》主条目死亡空间:野兽新闻2025年7月21日⚫︎ Techland发布了《死亡空间:野兽》的全新预告片,以讽刺幽默的方式展现了即将登场的卡斯托森林场景。视频由海狸博伯(Bober)主持,呈现出一则欢快的旅游宣传片风格,但很快便陷入混乱,该地区爆发的僵尸危机成为画面的主导。阅读更多:《死亡空间:野兽》最作者 : Ethan May 10,2026 -
 现在是你以我们发现的最低价格之一入手顶级 OLED 电视的绝佳机会,尤其是针对一款近期的 2024 年三星型号。目前,三星官网和亚马逊均提供 65 英寸三星 S85D 4K OLED 智能电视,售价仅为 $999.99,免运费。这款电视是您的 PlayStation 5 或 Xbox Series X 的完美搭配,因为它配备了 HDMI 2.1 接口,并支持高达 120Hz 的 4K 游戏刷新率。65" Samsung S85D 4K OLED Smart TV for $997.99### 6作者 : Hazel May 08,2026
现在是你以我们发现的最低价格之一入手顶级 OLED 电视的绝佳机会,尤其是针对一款近期的 2024 年三星型号。目前,三星官网和亚马逊均提供 65 英寸三星 S85D 4K OLED 智能电视,售价仅为 $999.99,免运费。这款电视是您的 PlayStation 5 或 Xbox Series X 的完美搭配,因为它配备了 HDMI 2.1 接口,并支持高达 120Hz 的 4K 游戏刷新率。65" Samsung S85D 4K OLED Smart TV for $997.99### 6作者 : Hazel May 08,2026










热门游戏



![A Father’s Sins – Going to Hell [Ch. 7 Public] By Pixieblink](https://img.laxz.net/uploads/67/1719578270667eae9eb6a75.jpg)





热门新闻

热门专题